用python实现解压一个zip文件到指定文件夹,使用zipfile库来实现,文件必须是zip格式的:
首先要引入os,zipfile两个包:
import zipfile
import os
from shutil import *
新建一个解压函数来实现解压的操作:
def unzipFile(oriPath,goalPath):
'''
解决解压zip包时的中文乱码问题
:param oriPath: 压缩文件的地址
:param goalPath: 解压后存放的的目标位置
:return: None
'''
with zipfile.ZipFile(file=oriPath, mode='r') as zf:
# 解压到指定目录,首先创建一个解压目录
unzip_dir_path = goalPath
if not os.path.exists(unzip_dir_path):
os.mkdir(unzip_dir_path)
for old_name in zf.namelist():
# 获取文件大小,目的是区分文件夹还是文件,如果是空文件应该不好用。
file_size = zf.getinfo(old_name).file_size
# 由于源码遇到中文是cp437方式,所以解码成gbk,windows即可正常
new_name = old_name.encode('cp437').decode('gbk')
# 拼接文件的保存路径
new_path = os.path.join(unzip_dir_path, new_name)
# 判断文件是文件夹还是文件
if file_size > 0:
# 是文件,通过open创建文件,写入数据
with open(file=new_path, mode='wb') as f:
# zf.read 是读取压缩包里的文件内容
f.write(zf.read(old_name))
else:
# 是文件夹,就创建
os.mkdir(new_path)
然后执行方法:
unzipFile('h2bcc.zip','J:/项目/deldir/h2bcc/')
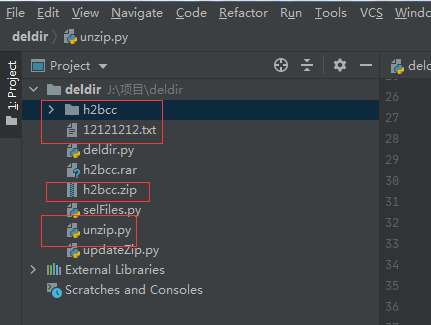
执行结果解压成功。
完整代码如下:
#coding=utf-8
import zipfile
import os
from shutil import *
def unzipFile(oriPath,goalPath):
'''
解决解压zip包时的中文乱码问题
:param oriPath: 压缩文件的地址
:param goalPath: 解压后存放的的目标位置
:return: None
'''
with zipfile.ZipFile(file=oriPath, mode='r') as zf:
# 解压到指定目录,首先创建一个解压目录
unzip_dir_path = goalPath
if not os.path.exists(unzip_dir_path):
os.mkdir(unzip_dir_path)
for old_name in zf.namelist():
# 获取文件大小,目的是区分文件夹还是文件,如果是空文件应该不好用。
file_size = zf.getinfo(old_name).file_size
# 由于源码遇到中文是cp437方式,所以解码成gbk,windows即可正常
new_name = old_name.encode('cp437').decode('gbk')
# 拼接文件的保存路径
new_path = os.path.join(unzip_dir_path, new_name)
# 判断文件是文件夹还是文件
if file_size > 0:
# 是文件,通过open创建文件,写入数据
with open(file=new_path, mode='wb') as f:
# zf.read 是读取压缩包里的文件内容
f.write(zf.read(old_name))
else:
# 是文件夹,就创建
os.mkdir(new_path)
unzipFile('h2bcc.zip','J:/项目/deldir/h2bcc/')
注意zipfile解压文件中文乱码问题解决方法:
# 由于源码遇到中文是cp437方式,所以解码成gbk,windows即可正常
new_name = old_name.encode('cp437').decode('gbk')