方法1.
BeautifulSoup库实现过滤html标签:
import re
from bs4 import BeautifulSoup
def guolvhtml(str):
soup = BeautifulSoup(str, 'html.parser')
print(soup.get_text())
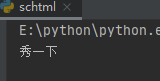
html='<h1 class="cybt">秀一下</h1>'
guolvhtml(html)
方法2.
re.compile实现过滤html标签:
import re
def guolvhtml(str):
pattern = re.compile(r'<[^>]+>', re.S)
result = pattern.sub('', str)
print(result)
html='<h1 class="cybt">秀一下</h1>'
guolvhtml(html)
方法3.
lxml etree实现过滤html标签:
from lxml import etree
def guolvhtml(str):
response = etree.HTML(text=str)
print(response.xpath('string(.)'))
html='<h1 class="cybt">秀一下</h1>'
guolvhtml(html)